Vyond | 2017
Information Architecture & Search Engine Design
Overview
Vyond (formerly known as GoAnimate) is an online SaaS-based application that enables people to create animated videos using drag and drop.
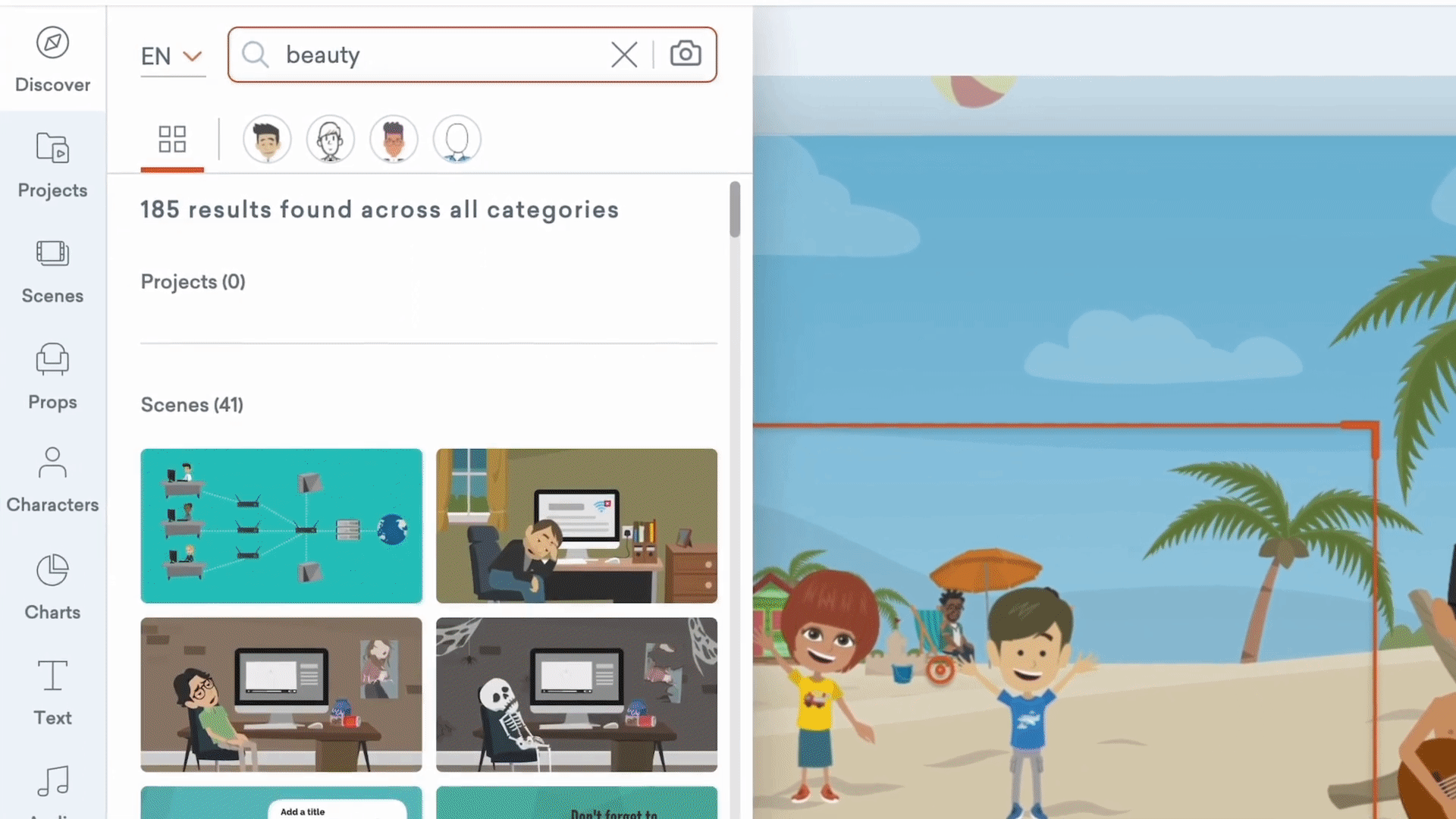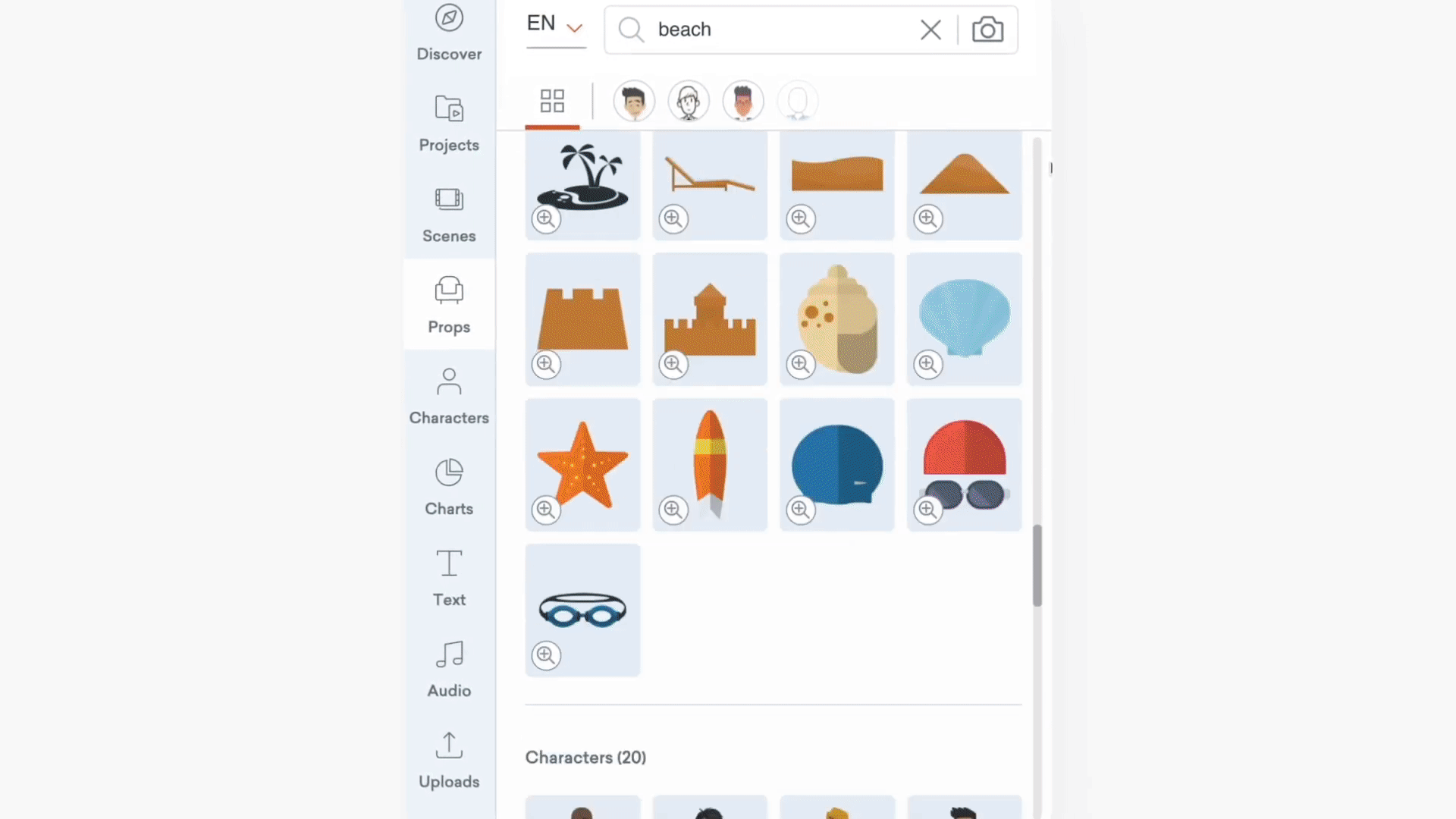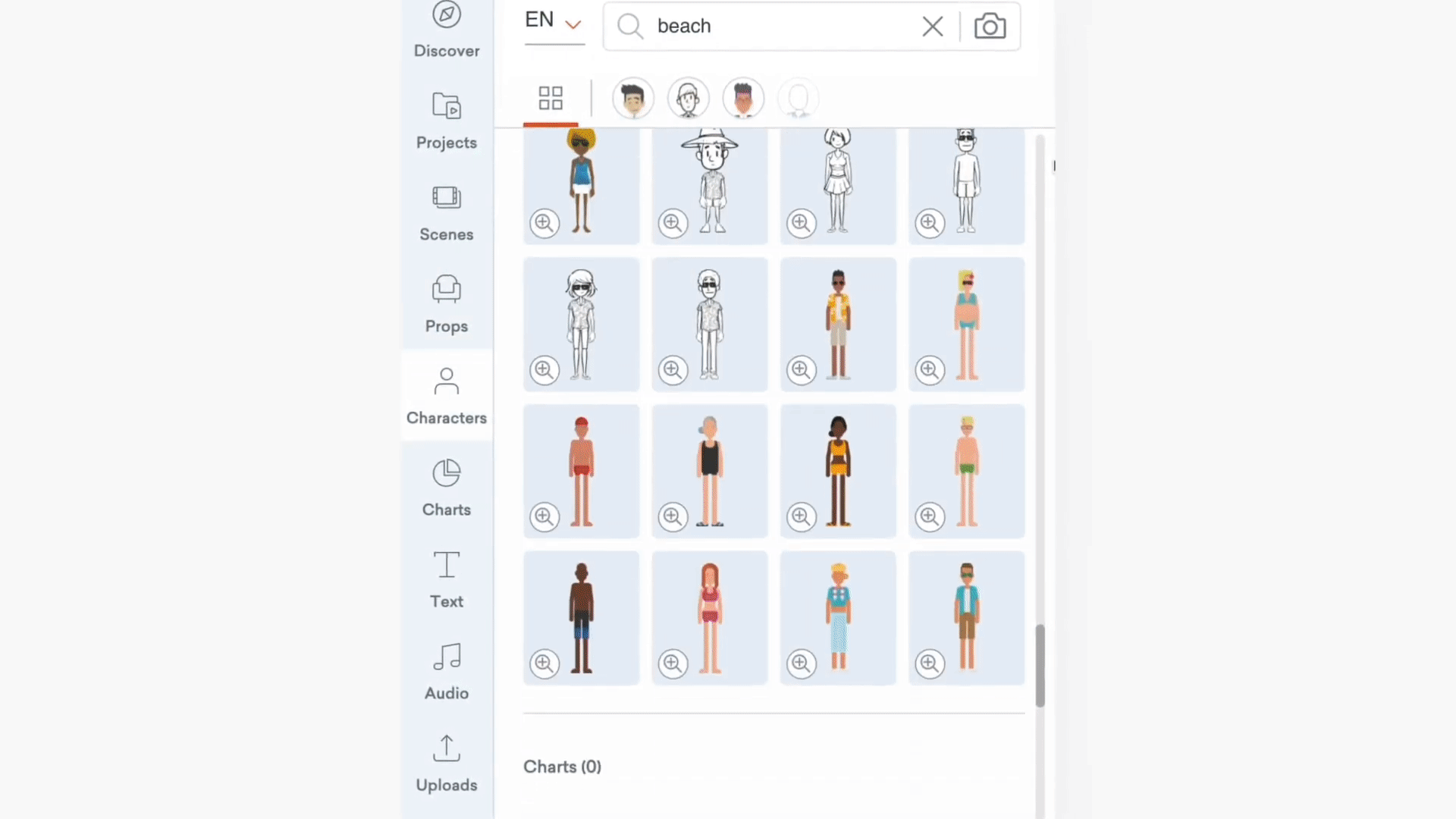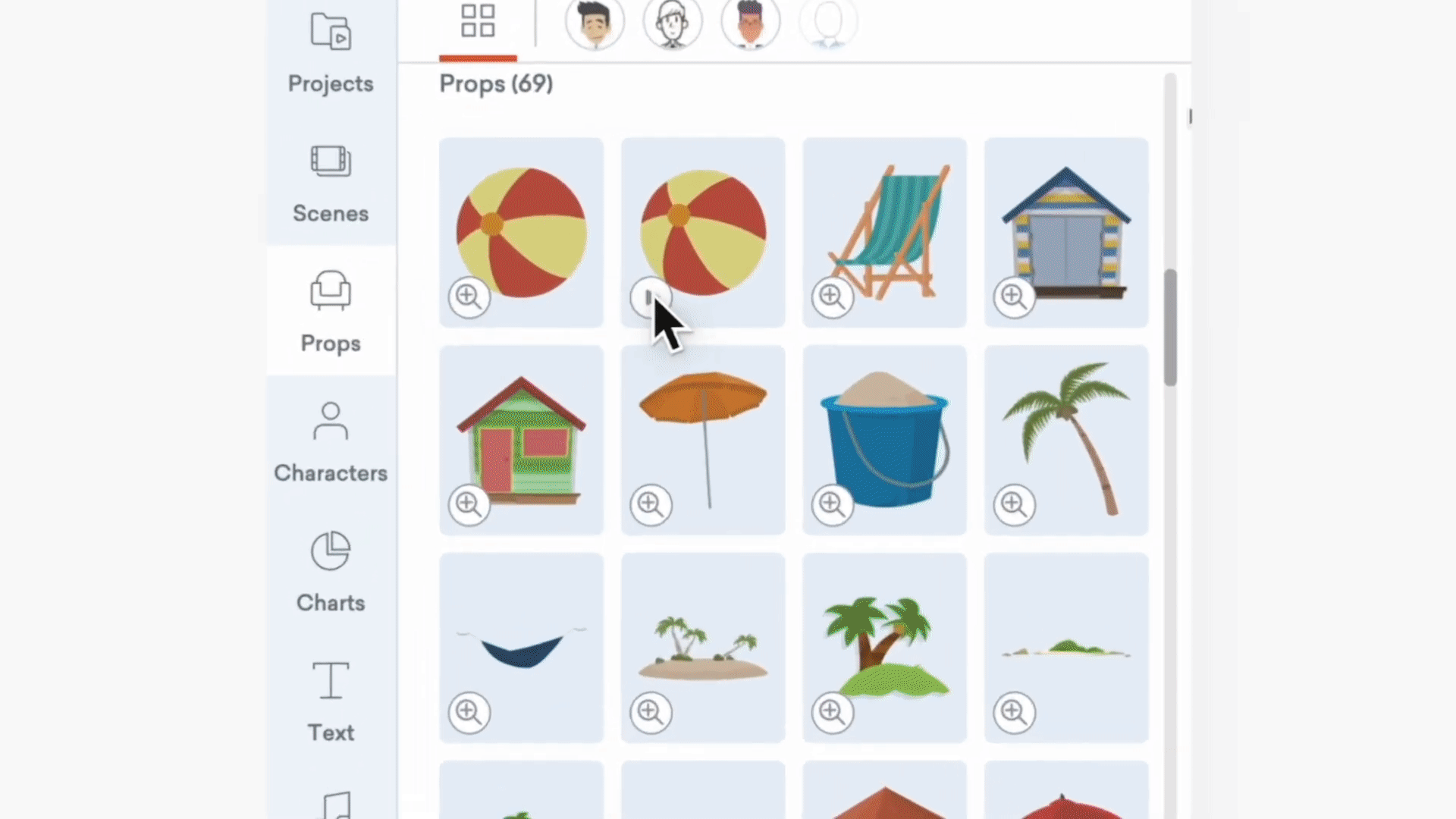
With 10,000+ props in their library that were categorized poorly and with very basic search capability, Vyond users had a hard time looking for what they wanted.
My Role
Research and design information architecture, produced tagging and metadata guidelines for content creators, and designed functional specs to improve the searching experience. I was the lead UX designer for this project and collaborated closely with the content team and one engineer.
The process
Understanding the existing system
To fully understand why the problem existed in the first place, I did in-depth interviews with the content team to understand how they work. The biggest problem I uncovered was that there were no guidelines on how content should be categorized. Each team member will organize content based on their own feelings. No wonder why contents are scattered along the place. On top of that, the search engine only supported search by file names, which was a really limited experience.
Break down the problem
There are 3 big problems I need to answer:
When should a concept become a category? For example, for an Office table, should it belong to a category called Office or Corporate? Why and why not? What about Furniture?
How to make the categorization scheme scalable? I want to create a scheme that not only support what we have currently, but can also support new contents in the future.
How can I make an item retrievable by using multiple keywords? For example, I want to find a Macbook. If I search Mac, Laptop, Electronics, or Apple I expect to be to find my Macbook. How do I make that happen?
Secondary Research

I recognized my problem wasn't unique; the challenge of organizing information predates my role as a UX designer. My research covered various concepts, examining product-based categorization systems like eBay and activity-based ones such as Meetup.com. I delved into global library classification schemes and explored government, yellow page, and recruiting websites for insights.
I concluded that items existing in multiple categories would be optimal for our tool. Concepts without the privilege of becoming a category will serve as tags for search engine retrieval. Below is a sketch of how I brainstormed categorizing a character.

First-hand research— Card sorting
We invited test 3 participants to our office for Open-ended card sorting exercises. We observed how they grouped things logically together and asked a lot of questions to understand why they chose to group things a certain way. I noted there are similarities between the participants and used that as a guide to create the categorization scheme.



Create categorization guideline
Based on the results from the card sorting exercise, I internally created a categorization guideline on how to categorize items within our library. The guideline underwent a few changes afterward to cover more topics and clarify the wording.
This guideline provides us with a unified understanding of how contents should be categorized. Instead of debating which content should go under which category, it saves time for the content team to focus on their expertise — creating remarkable contents.
We also collaborated with the development team to design an admin UI that allows the admin user to easily assign categories.


Tagging
A search engine retrieves information through metadata, also known as tags (e.g., the hashtag # on Instagram). It helps the search engine understand that an item carries multiple meanings. Fundamentally, a tag is a category.
It is easy to tag one or two items, but when you are tagging 10,000+ items, things start to become tricky. You will begin to miss some important tags, or you will start to overtag. Either way, the process is not efficient.
Tagging guidelines
To ensure that each item has good-quality tags, I developed a set of guidelines on how we should tag items. The team has to consider three questions for every item:
What is this item?
Where can you find this item?
What does it represent?
The tags will start from specific concepts and gradually move towards more generic ideas. For example, an "Office chair" will have tags that look something like: Chair → Office → Work...

Other considerations — Variance terms
Language is a tricky thing; there are different words that actually mean the same thing. For example, "Cell phone" or "Mobile Phone" refers to that thing you can use to call people while walking down the street.
To avoid spending time coming up with variations of terms and duplicate tagging, we grouped words with similar concepts or meanings together. We chose one term — the Controlled term — as the tag we will use internally. Other variations are called Variance terms.
The controlled term table is a very simple spreadsheet file. One column is the controlled term, and the other columns are the variance terms. Now when the user searches the variance terms, since variance terms and controlled terms are linked, we will be able to return results.

Front-end search experience improvement
After designing how we can come up with tags and how it would work in the backend, I started looking for some micro-interactions that can improve the search experience. Below are the interactions I added:

As users type in the search box, provide suggestions based on what they are typing. This helps us to a) educate the user on the items we have and b) save the user's time by reducing the amount of typing. Also, add an arrow keyboard shortcut to help users easily navigate between the suggestions.
Offer typo tolerance so that users do not have to worry if they misspelled something.
Bold the matched text.
Documentation
At this stage, I created a detailed document that describes how the search engine works, both in the front-end and in the back-end (the algorithm). I worked with the development team to refine the wording multiple times and ensure there is no ambiguity in how we wanted to make this project work.


The result
The project didn't just end because I shipped the feature. A good search experience requires continuous fine-tuning and follow-up. I set up a review cycle every two weeks to understand how well we were doing with the new search engine. We were mostly interested in two things:
Search terms that are "valid" but return 0 results. This means that the term should return results since the item exists in the library.
Search terms that were used a lot but return 0 results because the item searched doesn't exist in the library.


Based on the search log, I was able to make some fine-tune on the search experience. For example, we were able to identify items that were searched a lot but was not tagged and also identify the need to add more contents since users were looking for it.
What we planned to do in the future
We had plans to do the following tasks, which I think would bring the search experience to a higher level, but in the end, I had to drop the features due to time constraints.
Auto-ranking adjustment: Create an automatic system such that when an item is more popular than others, we will give that item more weight, so it will show up closer to the top in the search results.
Create a thesaurus library: A thesaurus library defines the closeness of each term. This means that apart from the regular search results we show to our users, we can also present relative search results, something very common in the e-commerce world. For example, "You may be interested in this..."
Reflection and lesson learned
Throughout this project, my biggest learning was to understand the concept of Controlled Terms and Variance Terms.
As I was working side by side with the content team, we faced the challenge of constantly thinking of variations of a concept, and try to put all those variations as tags. Things start to become messy as some items will have like 30 tags because of the team trying to cover every possible keyword we can think of.

It is after I picked up the book: Information Architecture for the World Wide Web — aka, the polar bear book which taught me the concept of Controlled Terms and Variance Terms and the art of organizing information, things start to change and went more smoothly.
My biggest take away is that, although some books are really boring, sometimes you just need to bite the bullet and read it. After all, knowledge is power!